This is a tech post about ku, a game where you create worlds by speaking them to life. You can find an intro to the game here.
ku is a game about creating people, where the core mechanic is speaking. There is a lot of this. You go around the world shouting (typing) commandments. Occasionally you get a strongly-worded response from the heavens. You might have a face-to-face conversation with a character, where both of you are saying things to one another. How does it all work?
In the previous two posts, I introduced the language of ku and gave some examples of how the player uses it to create meaningful concepts. Today I will be talking about the main piece of technology that makes the language function behind the scenes: the ku language compiler. My plan this time around is to give a whirlwind tour without going into too much depth on any topic in particular. Future posts will focus in on specific components.
Alright, let’s get started!
Implementing the language of ku requires a little bit of compilers knowledge. What I find interesting is that for ku’s use case, you need to take what you know about compilers in practice–usually used for translating programming languages to machine code–and spin it in a different direction.
What is this use case? Let’s break it down:
You talk to characters, and they talk to you. This means that our “compiler” must work both ways: translating from words that you type, but also to words that you can read. Right off the bat we see that the design will have to be bidirectional: we will have to both scan and generate text in the language.
You make magical commandments that affect the behavior of your civilization, and all of its people. This means that our compiler also has to target some kind of “AI machine” backend as well.
So we have two inputs, and three outputs:
Note: I say “text” here, but because of the way the language is designed, the game can also synthesize audio (speech) for these streams! I’ll leave more discussion about how this works for later.
Of course, when talking about multiple IO streams, it makes sense to consider an intermediate representation (IR)… something lightweight and easy to work with in code that makes it simple to translate between all of the above, like an abstract syntax tree (AST).
How about an example?
Let’s say we have a person, and their name is kasutaki.
They want to say, “I am alive,” a common greeting in ku.
This demonstrates the “character knowledge ⇒
readable text” stream from above
in a very basic way.
We begin with some data
belonging to the kasutaki instance
of the soul knowledge model
(pseudocode):
Soul {
name: "kasutaki"
// etc.
}Using this, we construct the AST for the sentence we would like to generate:

(For a refresher on what a “prime” is, check this out)
From this, the compiler generates a sentence in the language that the player can read:
( 1 )
ma kasutaki mu saku mi ya
the personkasutakiis alive
lit. “kasutakiSOULis”
(For a primer on reading the language of ku, see this post)
Another thing that makes the language of ku different–something I find particularly interesting–is its grammar. As I have mentioned in the past, the language of ku doubles as both a language of conversation (you can speak it with your friends if you want to) and a language of AI behavior. In other words, it is both a “real” language and a programming language. And the compiler must be able to handle this.
In the game, I differentiate between what I call the “divine” language (what you use to make decrees about how your AI civilization behaves) and the “profane” language (what you and the characters use to talk to one another). But in a sense, they are the same language, under the same unified grammar. It just so happens that the divine language is a subset of the profane language, and is handled by the compiler a little like a declarative programming language.
Let’s unpack that. First of all: in order to parse arbitrary sentences in the language of ku, we need a grammar that specifies symbols at the same level as parts of speech: nouns, verbs, et cetera. This is the language’s “natural” grammar, and all input must pass through it before any other processing is done.
But once our parser eats a valid input sentence in this grammar–converting it to some form of IR–we need to specify another grammar on top of this IR. This metagrammar is more strict, and specifies symbols at a level that is relevant to the AI machine backend.
In other words: of all the possible grammatically-correct sentences that can be produced in the language, only some of them are actually meaningful. Most of the complexity in ku’s compiler lies in the bits that deal with these semantically-relevant sentences.
To illustrate this,
let’s take a look at another example.
This time we’ll try the divine stream,
i.e. “player input text ⇒
AI machine code.” Here’s a sentence that the player might type
(copied verbatim
from the previous post on ku sentences):
( 2 )
ku ma nasaya nu saku mi manu yatasu na ma saku mi numa
commandment: a person’s “nasaya” shrinks when they eat
lit. “nasayaofSOULDOWNCHANGEwhenSOULCONSUME”
First, the compiler translates this text to an AST, using the natural grammar:
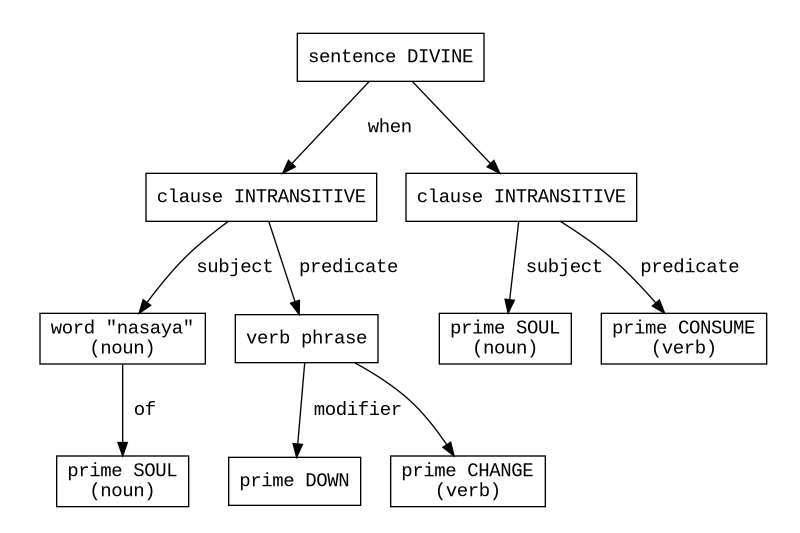
The input checks out and this is a valid AST. Time to transform this to a form more relevant to the semantics of the AI backend, using the divine metagrammar:
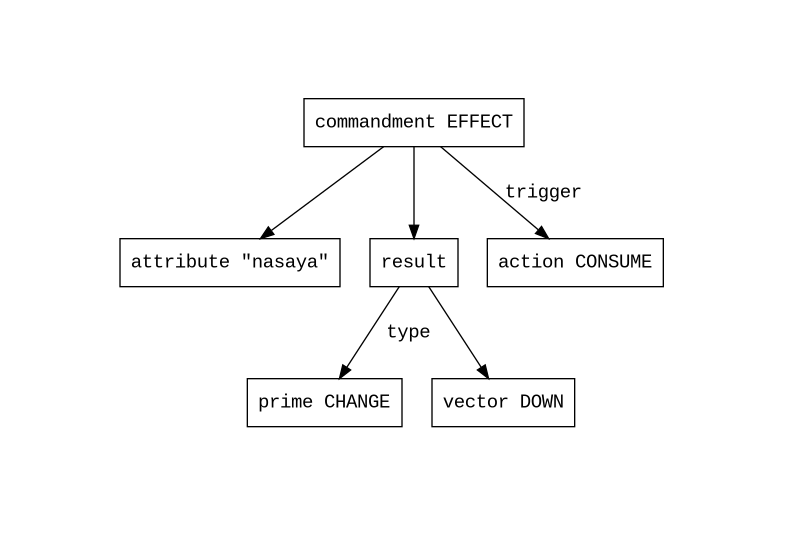
Finally, this IR is converted to data, and used to register an effect in the AI engine. Perhaps something like this (pseudocode):
Effect {
attribute_id: 0
delta: -.33
trigger_action: CONSUME
// etc.
}I talk about “the” metagrammar as if there is only one, but actually there are two: one for the divine language and one for the profane language. In the case of the divine language, its metagrammar specifies declarative statements that, in their totality, act as an interface to the AI machine (and to other miscellaneous things, like the lexicon). The metagrammar for the profane language is a little more complicated, since it encapsulates things like questions and statements of facts. However, the two metagrammars share many semantic primitives and thus operate on many of the same kinds of symbols.
For example: both metagrammars utilize the concept of an action. In short, an action is more than just a verb–it’s something that only people can do.
CHANGE is not an action, but MOVE is. The difference in semantics is important, because MOVE represents a primitive behavior that the AI engine can schedule for a character, whereas CHANGE is just a word used to make writing certain kinds of sentences (like the one above) possible.
We’ll discuss more about this kind of thing
when I make a post about the AI engine.
This brings us to the language of ku’s type system, another unique component. At the lowest level, the type of a word is its part of speech. But when it comes to the AI machine, certain classes of words have different semantics than other classes, regardless of their part of speech. Is a given word a prime, or did the player create it themselves? Does it refer to an attribute or an action? Is it a name? And so on.
Every word in the language can be redefined by the player at any time, even the basic particles. Because of this, the language of ku technically doesn’t have any keywords! Therefore, the lexical analyzer can’t really tokenize by itself. Instead, all words are checked against the player’s personal lexicon (their book of words) as they are scanned. The lexicon contains the rich type information necessary to resolve the meaning of any input string (and does so in a performant way).
As an example, here’s the result of using the lexicon
to query the full type information of the string "CONSUME"
(assuming the prime CONSUME is bound to numa,
as we’ve been using it so far):
word type
|
:
|
WORD_LOCAL
|
local (en-us)
|
:
|
"CONSUME"
|
speech type
|
:
|
VERB_INTRANSITIVE
|
is prime
|
:
|
YES
|
=> prime
|
:
|
PRIME_CONSUME
|
defined
|
:
|
YES
|
=> definition
|
:
|
"numa"
|
AI relevant
|
:
|
YES
|
=> AI type
|
:
|
ACTION
|
=> AI action
|
:
|
ACTION_CONSUME
|
Different parts of the compiler
require different chunks of this data,
depending on how much information they already have.
For example,
the scanner might see the input "CONSUME"
and would then need
to assign a part of speech to it for the parser.
On the other hand, the profane text generator
might begin with an AST containing a [prime CONSUME] node
and would then need to append the string "numa"
to a sentence that is later spoken ingame.
(If it seems weird that "CONSUME" is in English,
check out this
section on “locals”)
What else makes writing a compiler for the language of ku different than writing one for a traditional programming language?
Well, the language of ku doesn’t really look (or sound) like a programming language. It is limited to its own monosyllabic alphabet, as we have seen. There are no special characters or punctuation marks, aside from the hyphen. Also, “heavenly rebukes” (error messages) have to be intuitive and fun. This is a game, after all!
So as you can see, the language of ku is a bit different than the ones you might be used to. But its compiler does have most of the parts you’d usually expect. Next time I’ll start from the beginning–typing things into the game–and we’ll continue to explore from there.